The 6-Layer Shield — Architecting for Agents
Agents don't read documentation — they hit walls. The 6-Layer Shield is an architectural model that turns your codebase into a habitat with mechanically enforced boundaries, so agents can't drift into chaos.
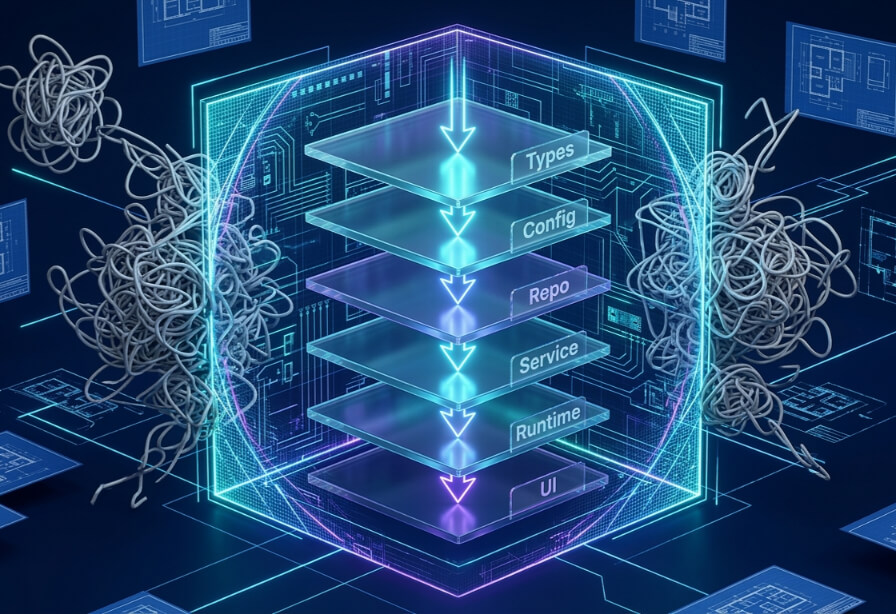
In Part 1, I introduced the horse and the harness — the idea that AI agents are powerful but directionless without infrastructure to constrain them. In Part 2, OpenAI's Harness team proved it at scale: 1,500 PRs, a million lines of code, zero typed by a human.
But those posts left a practical question unanswered: what does the harness actually look like on the inside?
This post answers that question. The 6-Layer Shield is the architectural model I use to turn a codebase from a loose collection of files into a mechanically enforced habitat — a place where agents can work fast without drifting into chaos.
The End of Architectural Drift
Traditional development relies on documentation to guide architectural decisions. A CONTRIBUTING.md explains the folder structure. A wiki page describes which modules can import which. A senior engineer reviews PRs and catches violations.
That works when the bottleneck is human typing speed. It falls apart completely in an agent-first world.
In a million-line codebase driven by high-throughput agents, documentation is effectively invisible unless it is mechanically enforced. Without rigid boundaries, an agent tasked with a "quick fix" will naturally take the path of least resistance — importing database models directly into UI components, bypassing business logic to hit raw APIs, leaking service-role keys into client-side JavaScript. Not because the agent is stupid. Because the agent is efficient, and the architecture didn't tell it "no."
As the OpenAI team discovered during their harness experiment: by limiting the edges where layers could interact, they reduced the complexity of the agent's reasoning task. Fewer valid paths meant faster convergence on correct solutions.
I keep returning to the horse metaphor. A horse in an open field will wander. A horse on a bridled path will run fast and straight. The 6-Layer Shield is the bridled path for your codebase.
The Standardized Layer Chain
The 6-Layer Shield is a unidirectional dependency graph. Each business domain is divided into six functional tiers, and the fundamental rule is simple: code may only depend forward — never backward.
| Layer | Functional Scope | Dependency Rule |
|---|---|---|
| Types | Core data shapes and machine-readable schemas | Root — no dependencies allowed |
| Config | Environment-specific settings and constants | May depend only on Types |
| Repo | Data persistence, retrieval, and DB logic | May depend on Types and Config |
| Service | Core business logic and domain rules | May depend on Types, Config, and Repo |
| Runtime | Platform integration and telemetry | May depend on any preceding layer except UI |
| UI | Presentation logic (React, Svelte, Web) | Final layer — may depend on any layer |
This isn't a suggestion. It's a constraint. And for agents, constraints are the only form of communication that actually sticks.
Layer 1: Schema-First Foundations
The foundation of the shield is the Types layer. But I don't mean TypeScript interfaces sitting in a /types folder collecting dust. I mean machine-readable schemas — JSON Schema, Zod, Pydantic — that the agent can reason over programmatically.
Here's a practical example. Instead of a vague type definition, we give the agent a schema with semantic metadata:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"title": "Task",
"type": "object",
"properties": {
"id": { "type": "string", "format": "uuid" },
"title": {
"type": "string",
"minLength": 1,
"description": "The user-facing title of the task"
},
"status": {
"enum": ["todo", "in_progress", "done"]
}
},
"required": ["id", "title", "status"]
}
The description fields aren't just for humans. They give the agent the semantic context it needs to generate valid data without intervention. When you provide .describe() metadata in Zod or Field(description=...) in Pydantic, you are writing documentation that the agent actually reads — because it's embedded in the schema the agent consumes, not in a markdown file it will never see.
This is the single most impactful thing you can do to reduce hallucinations: make the truth machine-readable.
Layers 2 and 3: Isolation of Environment and Persistence
The Config and Repo layers ensure the agent never leaks implementation details into the brain of the application.
Config centralizes environmental constants — API keys, feature flags, endpoint URLs. This lets the agent operate across different habitats (dev, staging, prod) without modifying a single line of logic. The agent doesn't need to know whether it's talking to a local Postgres instance or a cloud-hosted vector store. It just reads from Config.
Repo provides a collection-like interface for domain objects, abstracting away the specific database dialect. The Repository pattern isn't new — it's been a staple of clean architecture for decades, and for good reason. We used it long before agents existed to decouple business logic from persistence, to make codebases testable by swapping a real database for an in-memory fake, and to survive the inevitable "we're migrating to a new database" conversation that hits every mature product. The pattern earned its place in human-driven codebases. What's changed is that it's now critical infrastructure for agent-driven ones.
In a traditional team, a developer who bypasses the Repo layer and scatters raw SQL across the Service layer will eventually get caught in code review. An agent won't get that courtesy — it will replicate the shortcut everywhere, instantly, at scale. The Repository pattern gives the agent a single, clean interface — TaskRepo.findById(id) — that works the same whether the backing store is PostgreSQL, DynamoDB, or an in-memory mock for testing.
This separation is the safeguard that makes large-scale changes survivable. If you switch from a relational database to a vector store, the agent only needs to modify the Repo layer. The core business logic in the Service layer remains untouched. Without this boundary, a migration that should touch one layer ripples through the entire codebase — and an agent will happily propagate that ripple into places you never intended.
Layers 4 and 5: The Brain and the Habitat
The Service layer is the brain. It houses the application's core rules and coordinates data flow between persistence and presentation. It answers business-level questions: Is this user authorized to delete this task? Does this order exceed the daily limit? Should this notification be sent now or queued?
The Runtime layer manages the execution environment — platform-specific integration, observability, and telemetry. In advanced harness systems, this is where agents become genuinely self-aware. An agent can implement a database optimization and then query runtime metrics via LogQL or PromQL to verify whether performance requirements were actually met. Not "I think this is faster." Evidence. Data. The agent checks its own work.
This is what separates harness engineering from vibe coding. In a vibe-coded system, the agent implements a change and the human eyeballs it. In a harness-engineered system, the agent implements a change, queries the Runtime layer for telemetry, and either confirms success or rolls back autonomously. The human never has to look.
Layer 6: Presentation Without Logic
The UI layer is the final link in the chain. Because it sits at the end, it can consume data from any layer. But its responsibility is strictly presentation — rendering components, handling user interaction, displaying state.
A major failure mode in early agentic systems was agents stuffing sensitive logic into client-side JavaScript just to make things "work." Service-role keys in React components. Raw SQL queries in Svelte stores. Business validation duplicated in the browser because the agent couldn't find the Service layer.
By enforcing the 6-Layer Shield, the UI is forced to rely on the Service layer for security and validation. The agent literally cannot import from Repo into UI without the linter screaming. That's not a policy. It's a wall.
Mechanical Enforcement
Here's the thing that ties it all together. We don't ask agents to follow the layers. We make it impossible for them to break them.
Harness engineering prioritizes mechanical enforcement over human policy. The pattern is always the same: encode a constraint into a tool that runs automatically, surfaces a machine-readable error when the constraint is violated, and feed that error back into the agent's next prompt. The agent reads the error, understands the constraint, and corrects itself. No human involved.
Mechanical enforcement can take many forms depending on your stack and what you're protecting:
- Import boundary linters — reject backward layer dependencies at the module level
- Type system constraints — branded types and opaque wrappers that make illegal states unrepresentable
- CI gate checks — schema validation, test coverage thresholds, or dependency audits that block merges
- Commit hooks — fast local guards that catch violations before they reach the build pipeline
- Custom compiler plugins — deep structural rules enforced at the language level
The key is that the constraint is expressed in the build system, not in a wiki page. Any tool that produces a structured error the agent can read is a valid implementation.
The agent hits the wall, gets the error message, and corrects itself.
This is the self-healing loop that makes harness engineering work at scale. Every enforced rule is a permanent, tireless architectural reviewer that never takes a day off and never lets a violation slide because it's "just this once."
Example: The Linter Loop
One of the most practical implementations for JavaScript and TypeScript codebases is eslint-plugin-boundaries. It lets you define folder-based import graphs that trigger a build failure if a backward import is attempted:
// eslint.config.js
export default [{
settings: {
"boundaries/elements": [
{ type: "types", pattern: "src/types/*" },
{ type: "config", pattern: "src/config/*" },
{ type: "repo", pattern: "src/repo/*" },
{ type: "service", pattern: "src/service/*" },
{ type: "runtime", pattern: "src/runtime/*" },
{ type: "ui", pattern: "src/ui/*" }
]
},
rules: {
"boundaries/element-types": [2, {
default: "disallow",
rules: [
{ from: "config", allow: ["types"] },
{ from: "repo", allow: ["types", "config"] },
{ from: "service", allow: ["types", "config", "repo"] },
{ from: "runtime", allow: ["types", "config", "repo", "service"] },
{ from: "ui", allow: ["types", "config", "repo", "service", "runtime"] }
]
}]
}
}];
When an agent tries to import a Repo module from a UI component, the linter fires. That error message gets fed back into the agent's next prompt. The agent reads the error, understands the constraint, and corrects itself.
The Shield in Practice
After 13 years of building systems, I can tell you that the hardest architectural problems aren't technical — they're social. Getting an entire team to respect layer boundaries requires constant vigilance, code reviews, and the occasional awkward conversation.
Agents don't have social dynamics. They don't cut corners because they're tired or because the deadline is tomorrow. They follow constraints exactly — but only constraints that are mechanically expressed. The 6-Layer Shield takes the architectural discipline that used to require human willpower and encodes it into the build system itself.
The result is a codebase where the path of least resistance is the correct path. Where an agent generating a new feature is guided by the architecture into the right layer, the right abstractions, and the right dependency direction — not because it understood your wiki page, but because every other direction triggers a build failure.
That's not hoping the horse knows the way home. That's building the road.
References
- Alex Lavaee, OpenAI's Agent-First Codebase Learnings
- GTCode, Harness Engineering: Building Systems for AI Reliability
- NXCode, Agentic Engineering: Complete Guide
- Anthropic, Claude Agent SDK: Structured Outputs
- npm, eslint-plugin-boundaries
- InnoQ, From Vibe Coder to Code Owner
This is Part 3 of the Harness Engineering series. Part 1: The Scarcity Inversion. Part 2: The OpenAI Harness Benchmark.