Context Rot: Why Your Agent Gets Dumber the Longer It Works
LLM reasoning decays as conversation history grows. The fix isn't prompting harder. It's decomposing features into subtasks where each one gets a fresh context window and reads its state from disk.
In Part 3, I laid out the 6-Layer Shield, the architectural model that turns a codebase into a mechanically enforced habitat for agents. Rigid layers, unidirectional dependencies, linter walls that agents hit and self-correct against.
But even in a perfectly structured codebase, there's a failure mode that no amount of architectural rigor can prevent from within a single session: context rot.
This post is about what happens when the horse gets tired, and the harness pattern that ensures it never has to run on fumes.
The "Malloc/Free" Problem of LLM Contexts
Traditional programming languages have explicit mechanisms to allocate and release memory. You malloc, you free. You new, you delete. The lifecycle is controlled.
An LLM conversation has no such mechanism. Every file the agent reads, every tool output it receives, every rejected code snippet it generates, all of it stays in the context window. There is no free. There is only accumulation.
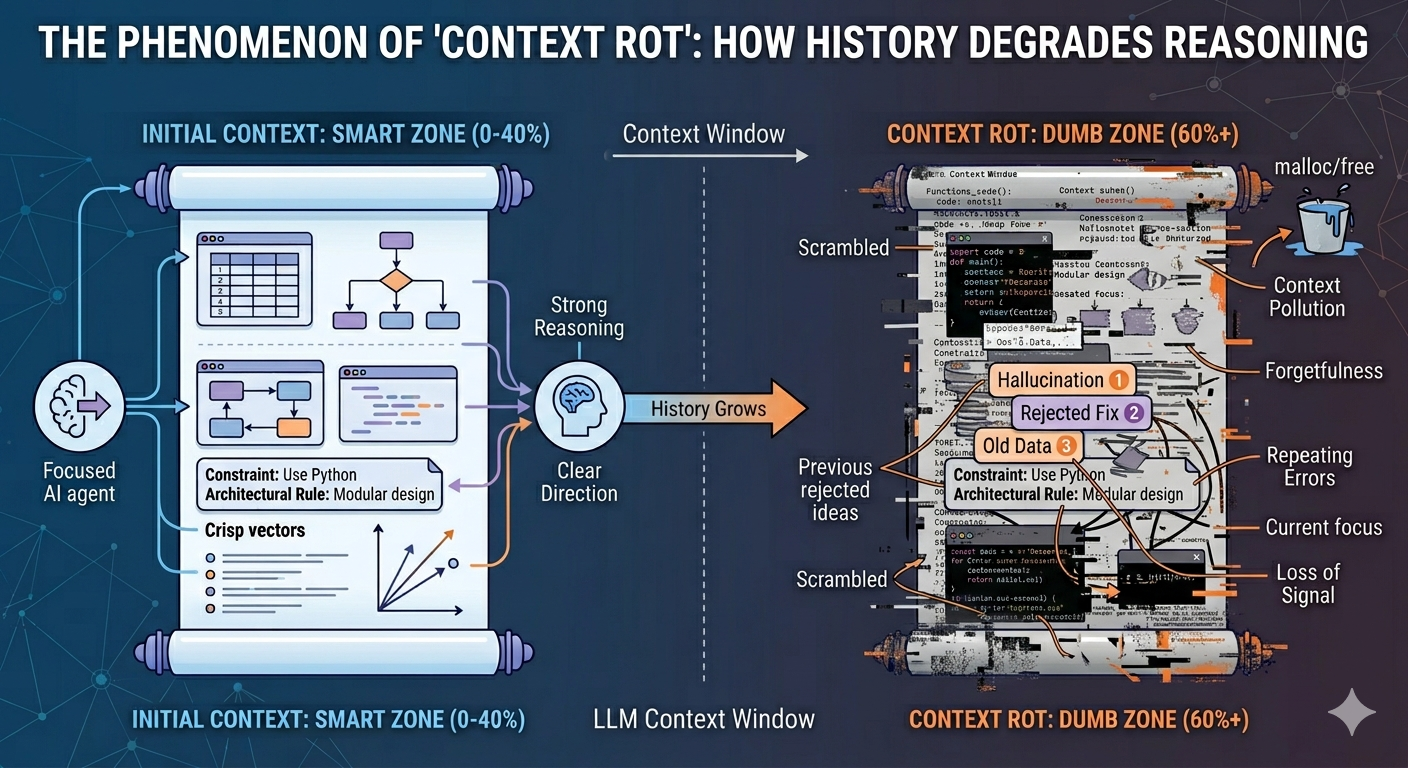
Think of it as a memory leak that you can't patch. Every interaction is a malloc with no corresponding deallocation. The context window fills with stale tool outputs, abandoned reasoning paths, and the ghosts of previously rejected approaches. This is context pollution, and it's the single most underappreciated failure mode in agentic development.
As this pollution accumulates, the agent crosses an invisible threshold. It enters what I call the Dumb Zone, the portion of the context window where reasoning capabilities plummet because the signal-to-noise ratio has collapsed.
The Smart Zone and the Dumb Zone
Not all parts of the context window are created equal. LLM attention is strongest at the beginning and end of the window, a well-documented phenomenon sometimes called the "lost in the middle" effect. In practice, this means the first ~40% of the context window is where the agent does its best thinking. I call this the Smart Zone.
Beyond that threshold, you're in the Dumb Zone. And in the Dumb Zone, the agent begins to:
- Forget core constraints. Architectural invariants established at the start of the session get buried under layers of tool output. The agent "forgets" that UI can't import from Repo, not because the rule disappeared, but because it's now 80,000 tokens away from the current attention focus.
- Repeat previously rejected ideas. The agent proposes the same fix it tried three iterations ago, because its memory of that failure has decayed into noise. You've seen this: the circular debugging loop where the agent keeps toggling between two broken approaches.
- Lose the original intent. The initial task description, the actual goal, gets diluted by the accumulated noise of every intermediate step. The agent starts optimizing for local coherence (making the current step "make sense") rather than global correctness (solving the original problem).
The agent doesn't get dumber. The context gets noisier. The effect is the same.
After 13 years of building systems, I can tell you: this is the exact same pattern as a developer who's been staring at a bug for six hours straight. The code hasn't changed. Their ability to see it clearly has. The difference is that a developer can take a break, get coffee, and come back with fresh eyes. An LLM can't, unless you build the mechanism for it.
How Harness Engineering Solves the Decay
Vibe coding treats the chat history as the system of record. Every decision, every context, every constraint lives in the conversation. When that conversation degrades, everything degrades with it.
Harness engineering inverts this entirely. The repository is the system of record. The chat is disposable.
This is the fundamental insight: move memory to disk. Instead of "prompting harder" within a decaying session, materialize every important decision as a versioned artifact that lives outside the context window entirely.
1. The Disk as Long-Term Memory
The primary mechanism is simple: treat design decisions and execution plans as versioned markdown artifacts. A PLAN.md file that captures the current task, its constraints, and the agent's progress. A STATUS.md that tracks which subtasks are complete. An ARCHITECTURE.md that encodes the invariants the agent must respect.
These files aren't documentation in the traditional sense. They're the agent's external memory, durable, version-controlled, and immune to context rot. When a new agent session begins, it reads these files and reconstructs the full picture from scratch. No accumulated noise. No decayed attention. Just the current state of the world, read fresh.
This is the equivalent of giving the developer a perfect set of notes before they sit down at their desk each morning. They don't need to remember yesterday's debugging session. They just read the notes and start working.
2. The Smart Zone Priority
Harness systems are designed to keep the agent perpetually in the Smart Zone. This is achieved through a three-tier system of progressive disclosure, giving the agent exactly the context it needs and nothing more.
| Tier | Name | Purpose | Example |
|---|---|---|---|
| Tier 1 | The Map | High-level project structure and core conventions | AGENTS.md, CLAUDE.md |
| Tier 2 | The Context | Task-specific prompts and domain knowledge loaded on demand | Skill files, task-scoped PLAN.md |
| Tier 3 | The Encyclopedia | Deep documentation accessed only when the agent explicitly needs it | API specs, schema definitions, reference docs |
The key is that Tier 3 content never enters the context window unless the agent specifically requests it. In a vibe-coded workflow, developers dump their entire architectural wiki into the system prompt "just in case." That's the equivalent of handing someone a 500-page manual when they asked for directions to the bathroom. It crowds out the signal with noise before the agent has even started working.
Progressive disclosure keeps the window clean. The agent starts with the map, loads context as needed, and queries the encyclopedia only when it hits a specific question. The result is a context window that stays in the Smart Zone for the entire duration of the task.
3. One Task, One Context
Progressive disclosure keeps individual sessions clean. But the real breakthrough comes from how you structure the work itself.
The pattern I've found most effective is brutally simple: break every feature into discrete subtasks, and give each subtask its own fresh context. Don't ask the agent to "implement user authentication." Ask it to "create the session token schema," then in a new session ask it to "build the login endpoint using the schema from src/types/session.ts," then in another new session ask it to "write the middleware that validates the token."
Each subtask gets a clean context window. Each one reads the current state of the codebase, including the artifacts produced by previous subtasks, with fresh eyes. The agent doing step three has never seen the debugging struggles of step one. It doesn't carry the scars of a failed approach from step two. It just reads the code on disk and executes its single, focused task.
This is why task decomposition isn't just a project management technique in agentic development. It's a context management strategy. The granularity of your subtasks directly determines how long each agent session stays in the Smart Zone.
Sub-Agents: Context Isolation at the Architecture Level
The "one task, one context" pattern isn't just an external orchestration trick. It's already built into the architecture of modern agentic tools through sub-agents.
When a parent agent spawns a sub-agent, something important happens: the sub-agent gets its own completely separate context window. It doesn't inherit the parent's conversation history. It doesn't see the parent's previous tool results, abandoned reasoning paths, or accumulated noise. It receives only the prompt it was given and the project-level configuration files like CLAUDE.md. Everything else starts from zero.
The sub-agent then does its work, reading files, running searches, executing multi-step reasoning, all within its own isolated context. When it finishes, only its final summary returns to the parent. All the intermediate tool calls, file reads, and dead-end explorations stay sealed inside the sub-agent's context and never pollute the parent's window.
This is context isolation enforced at the process level:
Parent Context (stays clean)
├── Main conversation
├── High-level task coordination
└── Summaries from sub-agents
Sub-Agent A (isolated) Sub-Agent B (isolated)
├── Task prompt from parent ├── Task prompt from parent
├── 50 file reads (internal only) ├── 30 grep searches (internal only)
├── 12 tool calls (internal only) ├── 8 tool calls (internal only)
└── Returns: 5-line summary └── Returns: 3-line summary
The parent orchestrates. The sub-agents do the heavy lifting. And the parent's context window never has to absorb the cost of that heavy lifting.
This is the same principle as the clean-slate loop, but operating within a single session rather than across multiple sessions. The parent agent stays in its Smart Zone because the expensive, context-heavy work happens in disposable sub-contexts. Each sub-agent is a fresh pair of eyes on a focused problem, exactly the pattern we want.
The practical implication is that well-designed agentic systems use sub-agents not just for parallelism, but as a context hygiene mechanism. Every time you delegate a research task, a file search, or a complex analysis to a sub-agent, you're keeping the parent's reasoning sharp by offloading the noise to an isolated context that gets discarded when the work is done.
Sub-agents don't just divide work. They divide context. That's what makes them powerful.
The Clean Slate Loop
At the macro level, the "one task, one context" pattern takes the form of an orchestration loop. The outer loop is mechanical. It doesn't need to be smart. It just needs to be relentless.
| Phase | Responsibility | Mechanism |
|---|---|---|
| Iteration | The agent reads PLAN.md and the current code, then executes the next incomplete subtask. |
Single-turn agent call with a clean context window. |
| Validation | Automated tests, linters, and type checks verify the change immediately. | Shell execution of the test suite. |
| Commit | If validation passes, the change is committed and PLAN.md is updated with progress. |
Git commit with structured status update. |
| Context Reset | The agent process is terminated. The conversation history is wiped. | The orchestrating loop moves to the next subtask. |
Here's what that looks like in practice:
#!/bin/bash
MAX_ITERATIONS=10
for i in $(seq 1 $MAX_ITERATIONS); do
echo "=== Subtask $i of $MAX_ITERATIONS ==="
# Fresh agent call, no shared state with previous iterations
claude --print \
"Read PLAN.md. Execute the next incomplete subtask.
Run tests. Update PLAN.md with results." \
2>&1
# Check if all subtasks are complete
if grep -q "STATUS: COMPLETE" PLAN.md; then
echo "All subtasks complete."
exit 0
fi
echo "Subtasks remain. Resetting context for next iteration."
done
echo "Max iterations reached."
exit 1
The elegance is in what this script doesn't do. It doesn't pass conversation history between iterations. It doesn't try to "summarize" the previous session. It doesn't maintain any state at all. The only shared state is what's on disk: the code, the tests, and the plan file. Everything else is born fresh.
Each iteration is a stateless function call: read the current state of the world, do one unit of work, write the results back, and die. The next iteration picks up from the written state, not from a degraded memory of the previous conversation.
The Decomposition Discipline
The quality of this pattern lives or dies on the quality of your task decomposition. Break the work into subtasks that are too large, and you're back to context rot within a single session. Break them too small, and you pay an overhead tax on context reconstruction that slows the whole system down.
The sweet spot I've found follows a simple heuristic: each subtask should produce one testable artifact. A schema file. An API endpoint. A React component. A migration script. If the subtask touches more than two or three files, it's probably too big. If it doesn't produce something a test can verify, it's probably too vague.
Good decomposition looks like this:
## PLAN.md
### Feature: User Authentication
- [x] Create session token Zod schema in `src/types/session.ts`
- [x] Add token generation utility in `src/service/auth.ts`
- [ ] Build POST `/api/login` endpoint using auth service
- [ ] Build GET `/api/me` endpoint with token validation
- [ ] Add auth middleware to protected routes
- [ ] Write integration tests for login flow
Each line is a self-contained unit of work. Each one can be executed by an agent with no knowledge of how the previous items were implemented, only that they were implemented, which the agent discovers by reading the codebase.
This is why I keep saying the repository is the system of record. The plan file tells the agent what to do next. The code on disk tells it what's already been done. The tests tell it whether it succeeded. The chat history tells it nothing it needs to know.
The granularity of your subtasks determines the freshness of your agent's reasoning.
Why Statelessness Wins
The stateless execution model has a counterintuitive benefit: it makes the system more reliable as tasks get harder.
In a stateful session, complexity is the enemy. Every additional step adds noise to the context. A ten-step refactor is dramatically more likely to fail than a two-step one, not because the individual steps are harder, but because the accumulated context degrades the agent's ability to execute step eight with the same precision as step one.
In a clean-slate loop, step eight runs with the exact same context quality as step one. The agent is equally sharp on every iteration because every iteration starts from zero. The difficulty of the task is determined by the complexity of each individual subtask, not by the cumulative weight of all previous ones.
This is the same principle that makes functional programming reliable at scale. Pure functions with no shared mutable state are easier to reason about, easier to test, and easier to compose. The clean-slate loop applies that principle to agent orchestration: pure iterations with no shared mutable context.
Every iteration is step one. That's the entire trick.
From "Prompt-and-Pray" to Mechanical Certainty
Context rot is the reason that "prompt-and-pray" workflows plateau. You can write the perfect prompt, give the agent perfect context, and watch it execute brilliantly for the first three steps. By step seven, you're watching an agent cheerfully produce nonsense with full confidence, unaware that its reasoning collapsed four steps ago.
Harness engineering solves this by refusing to play the game. Instead of trying to manage context decay within a session, it eliminates the session entirely. Decompose the feature. Give each subtask its own context. Let the agent read its state from disk, do one focused job, and exit. The orchestration loop, dumb, mechanical, tireless, manages the rest.
The software engineer's job in this paradigm isn't to write code or even to prompt the agent. It's to design the habitat: the plan files that encode intent, the test suites that validate correctness, the architectural boundaries that prevent drift, and the task decomposition that keeps the agent perpetually in the Smart Zone.
We stop compensating for the model's weaknesses by prompting harder. We start compensating by building systems that make those weaknesses irrelevant.
The keyboard becomes the tool you use to build the harness. The harness does the rest.
References
- Nelson Elhage et al., In-context Learning and Induction Heads, Anthropic's research on attention patterns and context utilization
- Liu et al., Lost in the Middle: How Language Models Use Long Contexts, foundational research on positional attention decay
- OpenAI, Harness Engineering, the experiment that validated agent-first development at scale
- GTCode, Harness Engineering: Building Systems for AI Reliability
- Anthropic, Claude Code Sub-Agents, documentation on context-isolated sub-agent architecture
This is Part 4 of the Harness Engineering series. Part 1: The Scarcity Inversion. Part 2: The OpenAI Harness Benchmark. Part 3: The 6-Layer Shield.